深入了解Redis的Pub/Sub
看到一篇深入讲解Redis中Pub/Sub的文章Redis Pub/Sub In-Depth,所以打算将它翻译出来,顺便深化自己的理解。
Pub/Sub(即publish/subscribe的简称)是一个在分布式系统中给不同组件互相通信的一种消息传递技术。这种消息传递技术与传统的点对点通信(即一个服务直接向另一个服务发送消息)不同,它是一种异步且可伸缩的消息服务,并且它可以将负责发布消息的服务与负责处理消息的服务分隔开。
在这篇博客中,我们会探索Pub/Sub的原理,以及Redis是如何实现这个通信模型的。我们会分析Redis中错综复杂的实现,将目光聚焦并深入到内存级别的实现的细节上,来让我们完全理解Pub/Sub机制,以及通过Redis完成的项目实践。
Pub/Sub入门
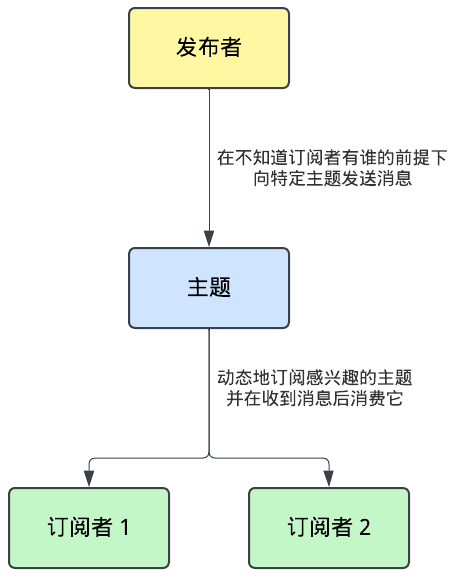
Pub/Sub是一个消息模型,它可以让分布式系统中的不同组件互相通信。发布者向一个主题(topic)发送信息,订阅者则从这个主题中接收信息。发送者在这个过程中可以保持匿名,当然如果在消息中包含了发送者的信息,那么订阅者也可以通过它来确定发送者的身份。Pub/Sub系统保证了消息可以被送达到所有对这个主题感兴趣的订阅者。在恰当的配置下,这将会是一个高度可扩展并且很可靠的消息传递系统,它将可以处理大量的数据。此外,在适当的大小、网络状况,以及订阅者的处理时间的前提下,Pub/Sub允许服务以1毫秒的延迟进行异步通信,因此它非常适合现代快速的分布式应用程序。
Pub/Sub模型
Pub/Sub的模型很简单,消息中介从发布者收到消息,然后将消息分发到各个订阅者。订阅者在得到消息后,就可以根据实际的场景对消息进行处理。基于发布者和订阅者的数量,这个模型通常可以被归为四类,即一对一、一对多、多对一、多对多。
| Pub/Sub类型 | 描述 |
|---|---|
| 一对一 | 包括一个发布者和一个订阅者。消息从发布者直接发送到订阅者。 |
| 一对多 | 包括一个发布者和多个订阅者。发布者向主题发送消息,所有订阅这个主题的订阅者都将收到这个消息。 |
| 多对一 | 包括多个发布者和一个订阅者。多个发布者都向某个特定的主题发送消息,订阅者会从这个主题收到消息。 |
| 多对多 | 包括多个发布者和多个订阅者。各个发布者都向某个主题发送消息,而各个订阅者都将收到这些消息。 |
Pub/Sub核心概念
在我们深入去了解Pub/Sub的细节和实现之前,我们需要先对Pub/Sub相关的核心概念有所了解。Pub/Sub系统包含多个组件,下表描述了其中的一些主要的组件:
| 组件 | 描述 |
|---|---|
| 发布者 | 发布者是一个应用或者服务,它会发出消息。 |
| 订阅者 | 订阅者是一个应用或者服务,它会接收消息。 |
| 主题 (topic) |
主题即消息的标题或信息源。发布者可以向一个主题发送消息,这些消息会被广播至订阅者。 |
| 消息 | 消息包含将在系统中被接收或传递的消息。 |
| 中介 (broker) |
中介负责指引消息在系统中的流动。它扮演着一个中间人的角色,负责在发布者和订阅者之间建立通信,并在它们之间交换信息。中介可以维护一个关于主题及其订阅者的列表,来帮助中介将从发布者收到的信息发送到正确的订阅者。 |
| 路由 (routing) |
路由指在系统中,信息从发布者流向订阅者,并依靠特定的订阅保障信息被送往正确的订阅者的过程。 |
Redis Pub/Sub
现在我们已经了解了关于Pub/Sub的一些抽象概念,并且知道了它是如何工作的。接下来我们需要深入到Redis针对Pub/Sub的实现,来了解消息从发布者发布出来,到结束于订阅者这个过程中,系统是如何通信的。
Redis通过在客户端之间实现一个简单而高效的消息系统来实现Pub/Sub。在Redis中,一个客户端可以“发布”一条消息到一个命名的通道,其他客户端则可以“订阅”这个通道来接收消息。
当一个客户端向这个通道发布了一条消息,Redis将会把这个消息发送到所有订阅了这个通道的客户端。这样,应用程序的不同组件之间就可以实时地通信并交换信息。
Redis Pub/Sub提供了一个轻量级、高速,并且可扩展的消息传递解决方案,并且可以用于各种场景下,比如实现一个实时通知、在不同微服务之间发送消息,或在一个应用的不同组件之间通信。
同步通信
Redis Pub/Sub是同步的。为了保证消息可以成功被传递,订阅者和发布者必须同时连接到Redis。
你可以将它想象成一个收音机电台,在调频到这个频道之后,你就可以收听它的内容。然而,在收音机被关掉之后,你就没法再收听了。
这意味着如果一个订阅者断开了连接,过了一会又连了上来,那么它将无法收到断开期间发出来的消息。也就是说,这限制了Redis Pub/Sub只能用在允许数据可能丢失的场景下。
发射后不管 (Fire & Forget)
“发射后不管”是一种信息传递模式,在这种模式下,发送方不会期望从接收方明确确认信息已经被收到。发送方只会将消息发出去,然后就继续开始做后面的事,不管消息有没有被接收方收到。
仅向外播散 (Fan-out Only)
Redis Pub/Sub只管向外播散消息,也就是说,当发布者发布了一条消息后,这条消息会被广播到所有当前活动的订阅者。所有订阅者都会收到这条消息的副本,不管它们是不是对这条消息感兴趣。
掀开Redis Pub/Sub的引擎盖
Redis最著名的功能是键值服务器。当客户端连接到Redis服务器后,它将会与服务器建立TCP连接,并开始向服务器发送命令。
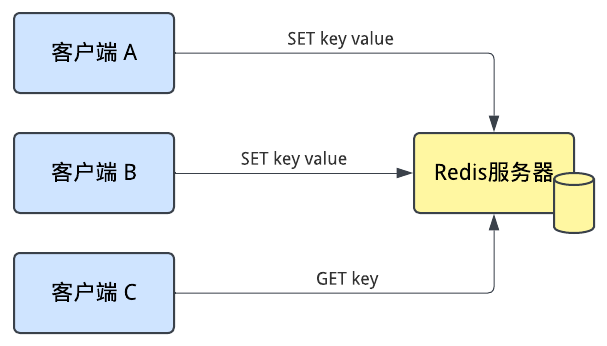
但是Redis也是个消息服务器!一个对topicA感兴趣的客户端可以向Redis服务器建立一个TCP连接,发送SUBSCRIBE topicA命令,然后等待与topicA相关的新闻。“新闻机构”也可以连接到Redis服务器,发送PUBLISH topicA message-data,然后所有订阅了这个主题的客户端都将收到这条价值连城的消息。

如果放大了看Redis里面发生了什么,我们可以想象Redis会跟踪每个套接字(socket)的订阅集:
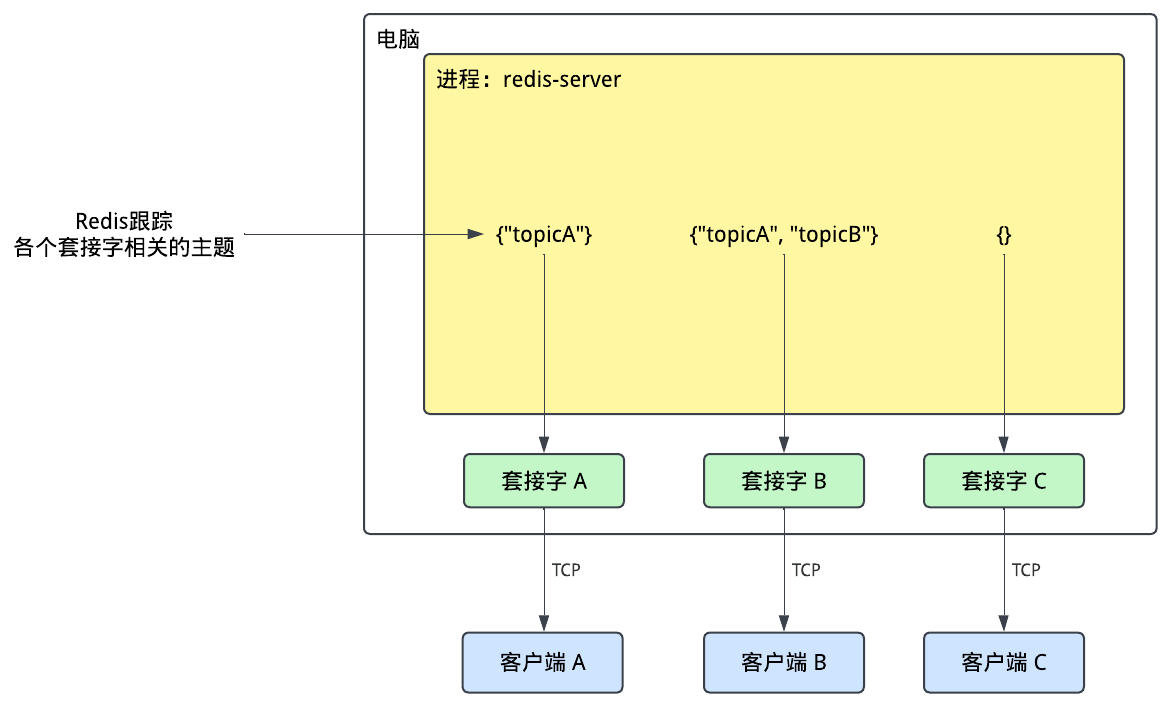
咱们继续深入看看Redis是怎么做的。
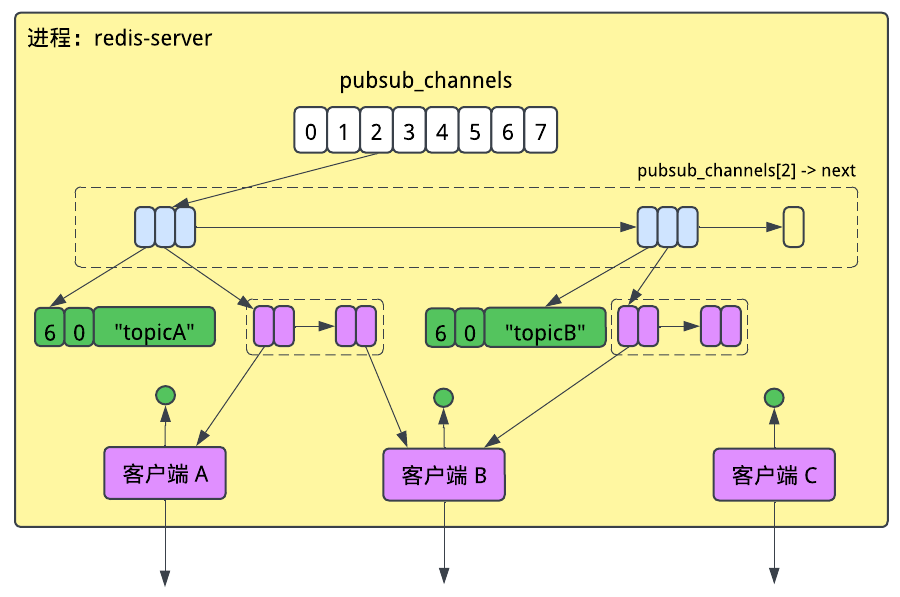
最初的Pub/Sub实现允许客户端发送三个新的命令:PUBLISH,SUBSCRIBE,和UNSUBSCRIBE。Redis使用了一个全局变量pubsub_channels来跟踪各个订阅,在其中Redis维护了一个通道名和订阅它的客户端对象的映射关系。每个客户端对象代表一个TCP连接的客户端,并通过其对应的文件描述符来跟踪。
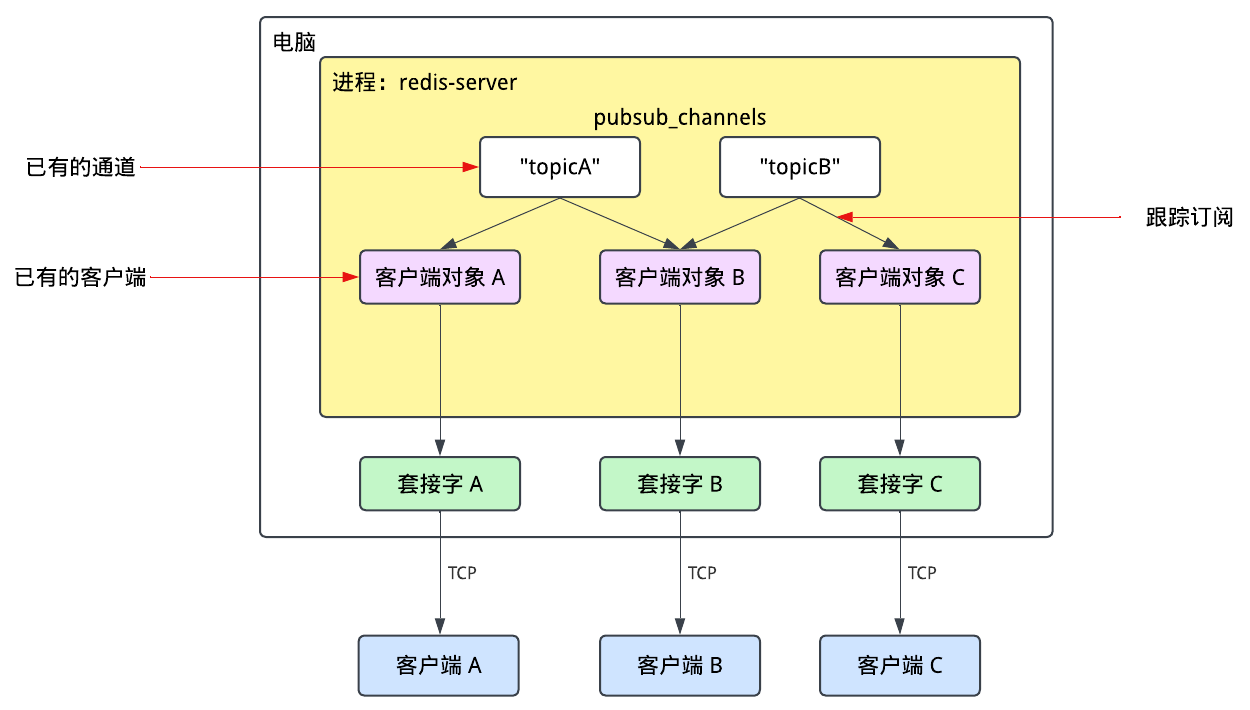
当一个客户端发送SUBSCRIBE命令后,它对应的客户端对象就会被加到对应通道的客户端对象集中。
在发布信息时,Redis会从pubsub_channel中找到这个主题对应的订阅者,并针对每个客户端启动一个计划任务来向对应的套接字发送信息。
处理连接断开
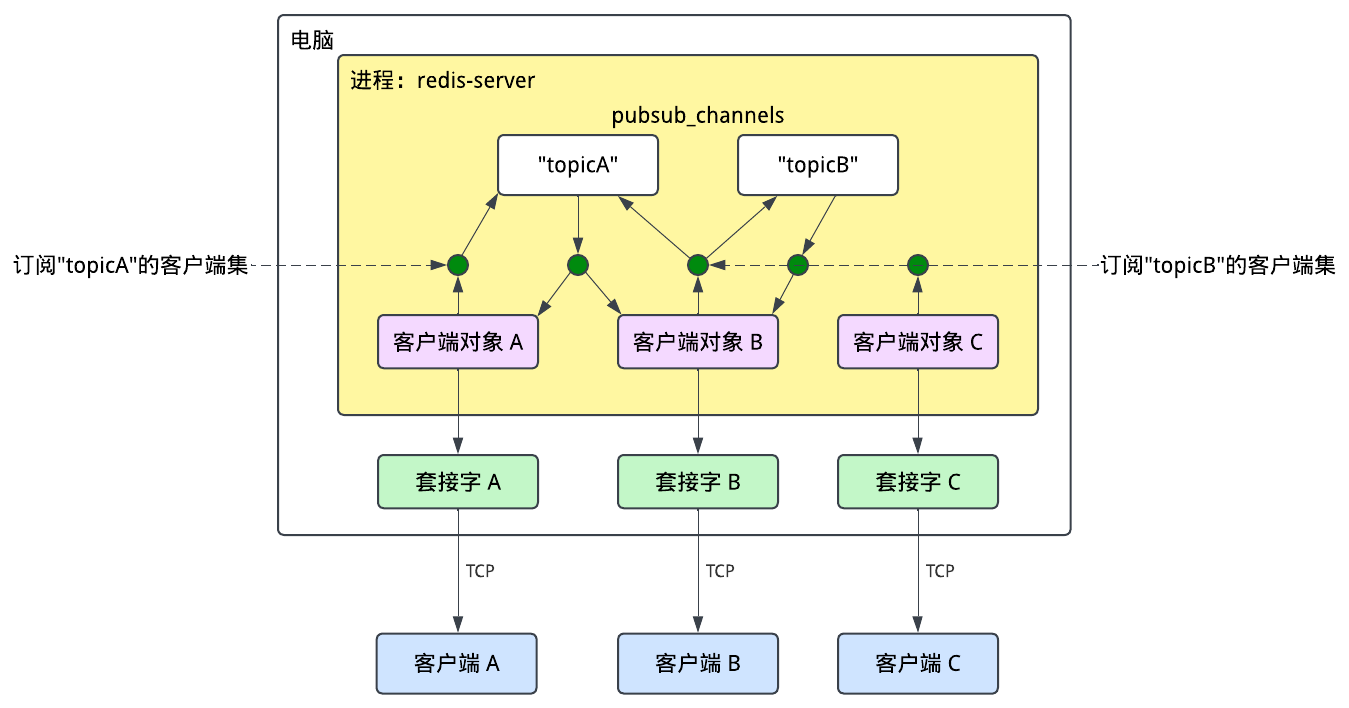
客户端的连接可能会因为客户端断开连接,或者网线被拔掉而断开。当有连接断开时,Redis必须将对应的订阅清理掉。假设客户端A断开了连接,那么为了将这个客户端从pubsub_channels中清除,Redis需要遍历每个通道(“topicA”和”topicB”),并从它们的客户端对象集中删掉它。
可想而知,遍历所有的通道的效率是非常低的。按道理,Redis只需要访问”topicA”这个通道,因为客户端A只订阅了它。为了将这个理论变成实际,Redis标记了各个客户端及其订阅的通道,并将其与pubsub_channels同步。这样,Redis就只需要访问这个客户端相关的通道,而不需要低效的遍历所有的通道。我们在图中可以将这些标记画成绿色的圆:
落实理论
我们已经知道,全局变量pubsub_channels的数据结构基本上就是一个Map<ChannelName, Set<Client>>,而每个客户端的订阅集就是个Set<ChannelName>。但是这些都只是一个抽象的数据结构,没法说明内存中是如何表现的。所以我们继续放大,看看内存中的样子。
pubsub_channels这个Map实际上是个哈希表,其中通道名会被哈希,然后放到一个2^n长的数组中的对应位置。
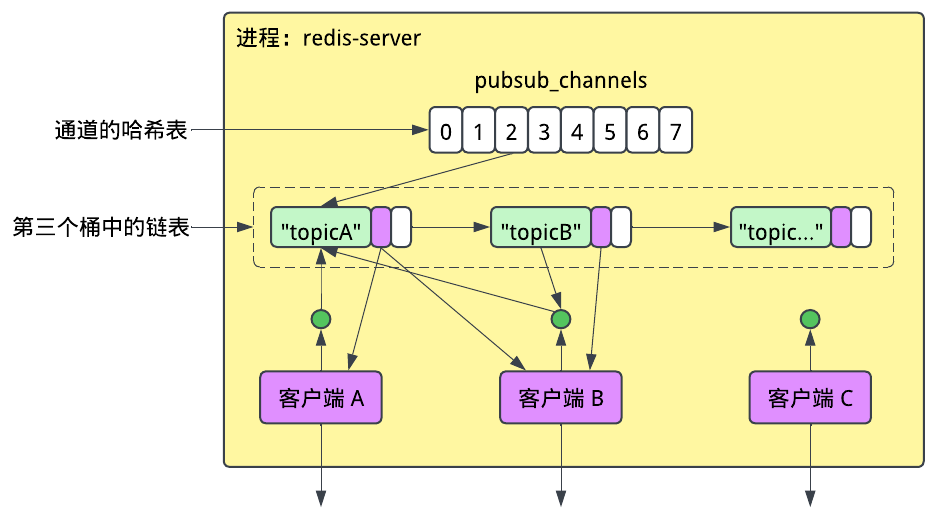
包含了8个桶的数组pubsub_channels是一块独立分配出来的内存空间。要发布消息到一个通道,首先它会将通道名进行哈希,找到它对应的桶,然后遍历这个通道相关联的各个客户端。然而不同的通道名又可能会被哈希到同一个桶中,为了解决这个哈希冲突问题,Redis使用了一个叫“哈希链”的方案,即每个桶都会指向一个保存着通道的链表。比如在上面的例子中,“topicA”和“topicB”都被哈希到了第三个桶中。实际上为了以防万一,Redis会在启动时为它的哈希函数选择一个随机的种子来尝试避免出现哈希碰撞,这也可以防止被恶意用户蓄意订阅到会被哈希到同一个位置的大量通道而导致性能下降。
在下图中,绿色的字符串是通道的名字,作为哈希表的键;紫色的是客户端的集合,作为哈希表的值。但“集合”在这里也是个抽象的概念,它在Redis中是怎样表现的呢?答案是,另一个链表!
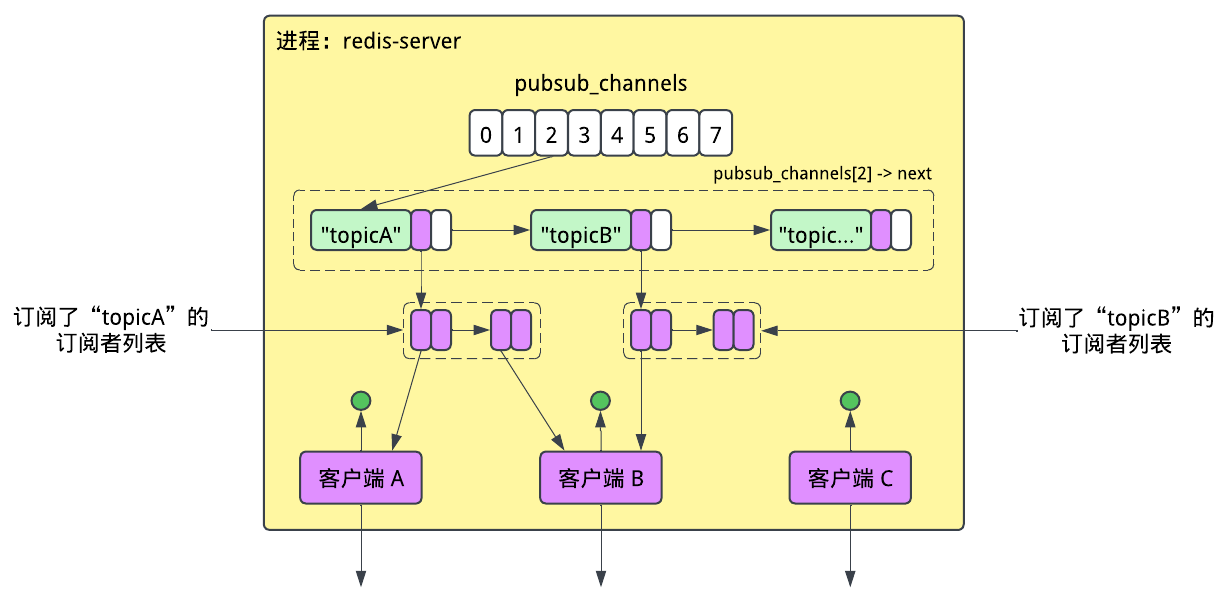
我们可能会觉得字符串“topicA”和“topicB”是在哈希链里面的,但实际不是。每个字符串都是独立分配的一块内存空间。字符串在Redis中被广泛使用着,它们甚至有自己的名字叫“简单动态字符串(Simple Dynamic Strings)”,其内容分三部分:已占用的空间、剩余的空间,和一个字符数组。
到现在我们已经快要到内存级别了,但是还有一件事没有提到,那就是每个通道的客户端集。在这里,Redis并没有选择用链表,而是用了另一个哈希表,其中通道的名字就是哈希表的键。
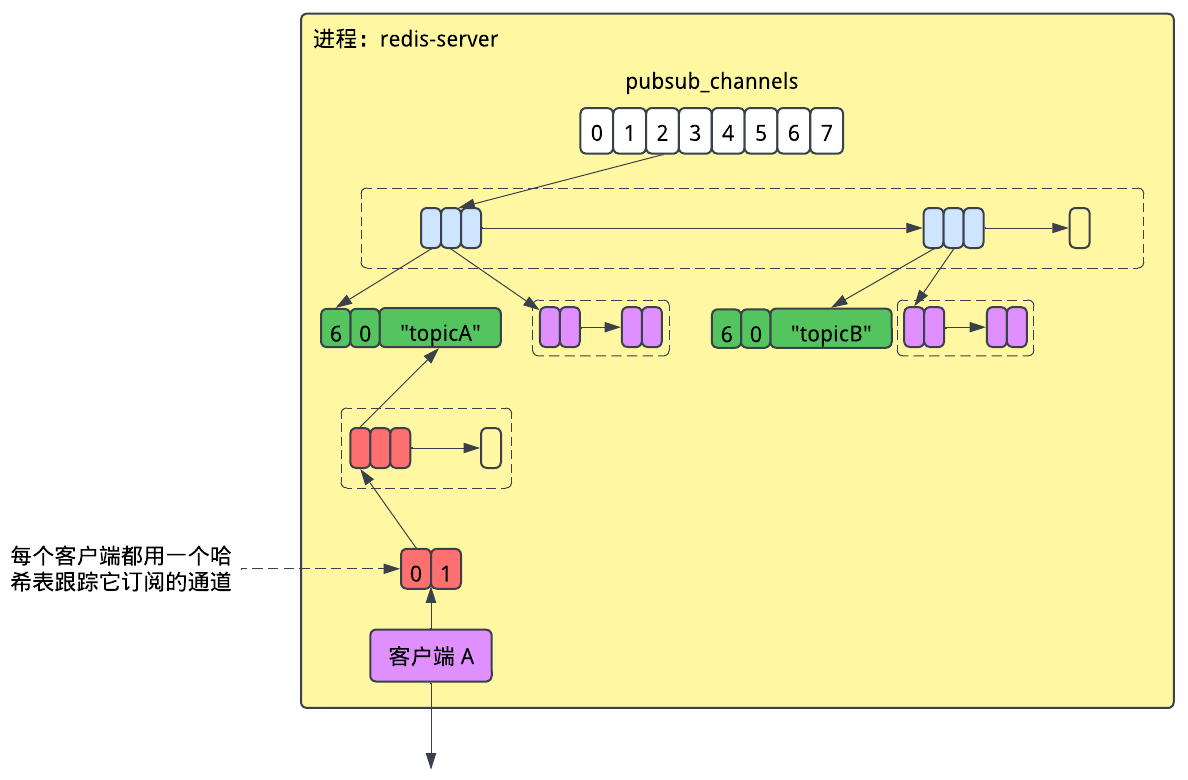
我暂时还不清楚为什么Redis选择用链表保存通道的客户端集,而又选择哈希表来保存客户端的通道集。我怀疑Redis选择在通道的客户端集上用链表是因为,链表更适用于发布的场景,因为在发布时会需要遍历它;而选择在客户端的通道集上用哈希表则是因为它更适用于订阅和取消订阅的场景,因为此时要做的是在里面做查找。如果你有更深入的理解,请告诉我。
需要注意的是,在每个客户端的哈希链上,指向它的值的指针是被忽略的,这片内存没有被用到。当用哈希表来表示一个集合的时候,我们只会用到它的键。相比较于我们从代码复用中得到的收益,这部分浪费不值一提。
终于,我们快要接近真相了:图中的每个方块都代表redis-server进程中分配的一块内存。现在我们来回顾一下PUBLISH和SUBSCRIBE的算法:
- 在
PUBLISH的时候,首先对通道的名字做一次哈希,接下来遍历哈希链,将要发布的通道名与哈希链中的各个通道名做比较。在找到我们要的那个通道后,从中得到它的客户端列表。然后遍历客户端列表,将消息发至各个客户端。 - 在
SUBSCRIBE的时候,首先像PUBLISH一样找到保存着客户端的那个链表,然后将新的客户端附加在链表的尾部。并且将要订阅的通道添加到客户端维护的哈希表中。
可以实时操作的哈希表
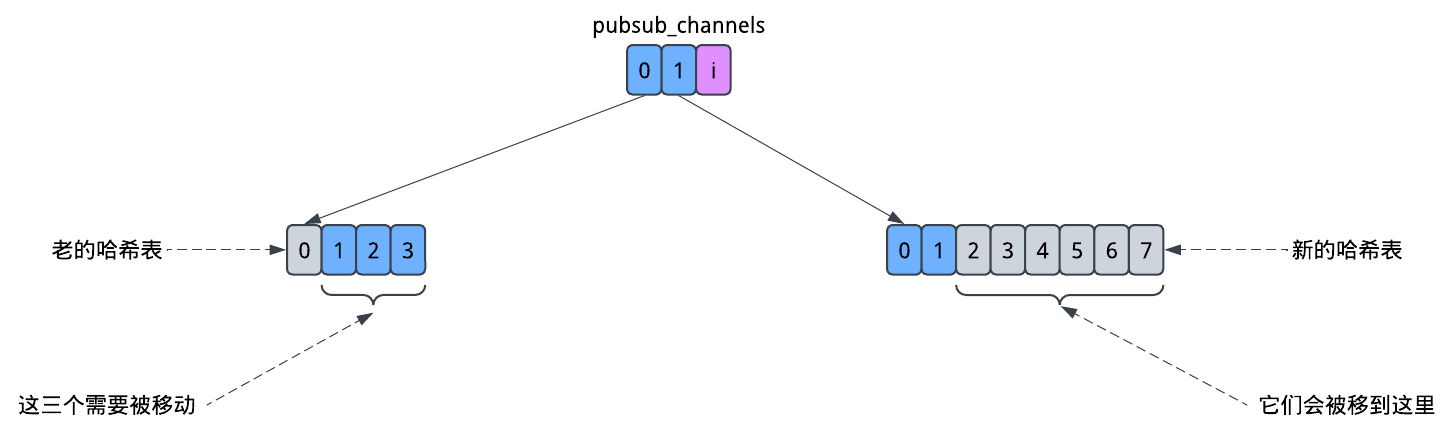
要注意这些哈希表的大小是不同的,而且都大概与其元素数量成比例。Redis会根据元素数量调整哈希表的大小。但是,Redis的设计目标是低延迟,而调整哈希表又是个比较耗时的操作。那么Redis是怎么做到在调整哈希表大小时不产生延迟尖峰的?
答案是:Redis会逐步的调整哈希表的大小。它在底层维护了新旧两个哈希表。假设pubsub_channels这个哈希表正在经历调整。
每当Redis对哈希表进行操作时(查询、插入、删除……),它都会稍微调整一下哈希表的大小。它会跟踪有多少老的桶被移动到了新的桶中,然后在每次操作中,它都会再移动几个过去。这样一来,调整大小的工作量就会被限制,使得Redis在调整期间也可以保证响应。
不再订阅昂贵的东西(Expensive unsubscribed)
在Pub/Sub中还有一个很重要的操作:UNSUBSCRIBE,它所做的与SUBSCRIBE正相反,它会使客户端不再订阅到指定的通道,也不会再收到来自这个通道的消息。那么利用上面说过的数据结构,你会怎么实现UNSUBSCRIBE功能呢?Redis是这样做的:
在UNSUBSCRIBE时,首先找到这个通道对应的客户端链表,然后遍历整个链表直到找到我们要删除的那个客户端。
也就是说,UNSUBSCRIBE操作的耗时是O(n),其中n就是客户端的数量。如果一个通道有大量的客户端订阅,那么UNSUBSCRIBE操作就会变得很昂贵。所以,你要么需要限制你的客户端数量,要么需要限制它们订阅的通道的数量。Pusher的一个优化就是去掉重复的订阅,数百万的Pusher订阅会被折叠为数量更少的Redis订阅。
Redis可以通过把存放客户端订阅的链表换成哈希表来优化,但也可能不会很理想,会导致发布消息稍稍变慢,因为遍历哈希表比遍历链表慢。Redis选择针对PUBLISH操作去做优化,因为它们比变更订阅更加常见。
按照表达式匹配订阅(Pattern subscriptions)
最初的Pub/Sub提供了PUBLISH、SUBSCRIBE和UNSUBSCRIBE三个命令。不久之后,Redis引入了一个名为“按照表达式匹配订阅”的新功能及其命令PSUBSCRIBE,这个可以让客户端订阅所有匹配了某个正则表达式的主题。
现在,如果一个客户端发送了命令PSUBSCRIBE food.donuts.*,然后一个发布者发送了命令PUBLISH food.donuts.glazed 2-for-£2,那么订阅者也会收到消息,因为food.donuts.glazed匹配了正则表达式food.donuts.*。
按照表达式订阅的实现是与普通的订阅完全不同的。除了全局的pubsub_channels哈希表之外,还有一个全局的pubsub_patterns列表。这是一个包含了pubsubPattern对象的列表,每个对象与一个客户端订阅的一个表达式相关联。类似地,每个客户端对象也有一个包含着它订阅的表达式的链表。下图展示了当客户端B订阅了drink?,同时客户端A和客户端B订阅了food.*之后,redis-server进程的内存的样子:
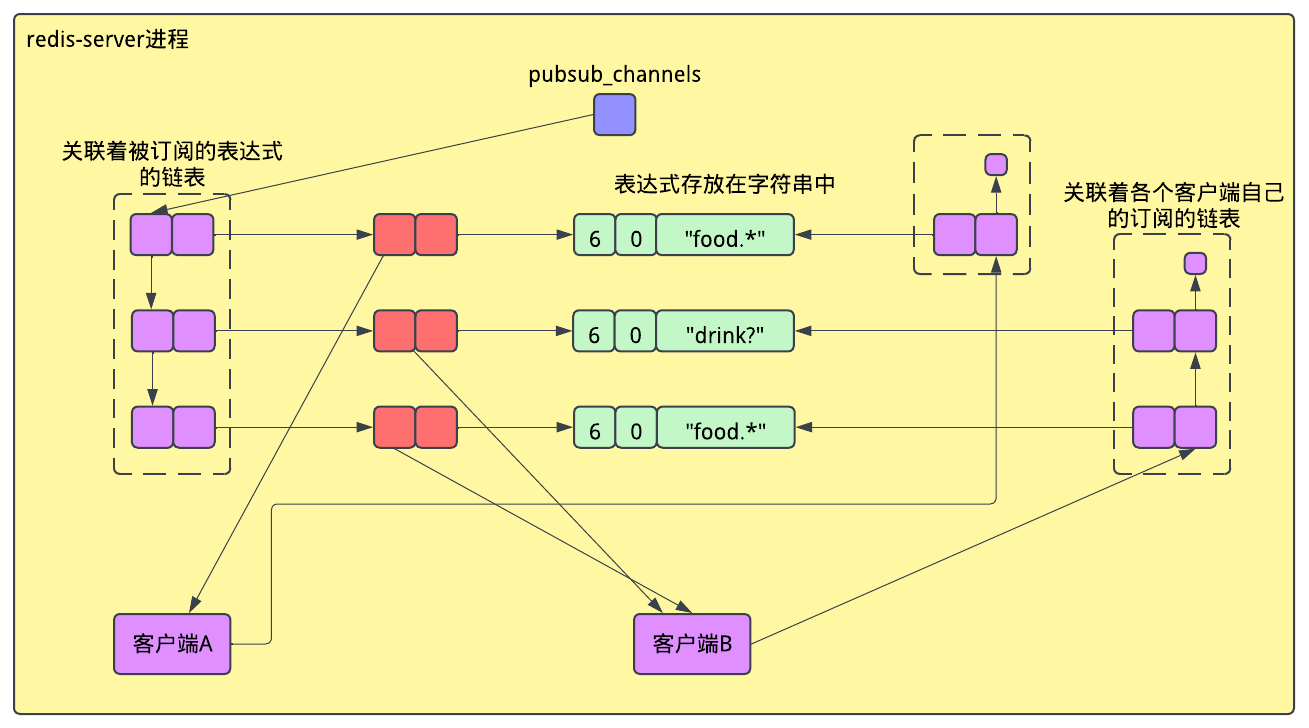
图示的左侧是一个全局的链表,每个节点都指向一个pubsubPattern,每个表达式在内存中都是字符串字面量。在图示的右侧,每个客户端都有一个关联着它的订阅的链表。
当一个客户端发送命令PUBLISH food.donuts 5-for-£1,Redis就会遍历pubsub_patterns列表,并将字符串food.donuts与每个表达式匹配。每遇到一个符合的匹配,Redis就会发送消息5-for-£1到关联的客户端。
这个实现可能有一个让你惊讶的点:如果多个客户端订阅到同一个表达式时,这些订阅不会被组合在一起。如果有10000个客户端都订阅了food.*,那么你将会得到一个包含了10000个表达式的链表,其中每个元素在发布消息的时候都会被匹配。这种设计假定模式订阅集很小,而且各不相同。
另一个会让你惊讶的点是,表达式都是以其原文存储的,它们并没有被编译。这一点尤其有趣,因为Redis的匹配函数stringmatch有一些有趣的坏情况。如下展示了Redis是如何把字符串aa与表达式*a*a*b相匹配的:
1 | stringmatch("*a*a*b", "aa") |
这种带有许多glob的恶意表达式会导致匹配的执行时间爆炸性增长。Redis的表达式语言虽然可以被编译成确定有限状态自动机(DFA),来让匹配耗时变得线性,但却没这么做。
所以长话短说,你不应该把Redis的按表达式匹配功能开放给不被信任的客户端,因为这可能会引来两种攻击:一种是订阅大量的表达式,另一种就是刻意制造的表达式。在Pusher,我们会非常小心地处理Redis的按表达式订阅功能。
Pub/Sub的使用场景
我们现在知道了Pub/Sub的技术细节,以及在Redis中是怎么实现的。接下来我们看看有哪些使用场景。
Redis提供的异步集成功能提高了系统的整体灵活性和稳定性,使其能够满足各种场景,包括:
- 实时消息和聊天
- 物联网设备
- 新闻发布和警告
- 分布式计算和微服务
- 事件驱动的架构
- 组件间解耦,以及减少依赖
- 扇入处理(Fan-in processing)—— 将多个消息组合成一个消息的过程被称为扇入处理。
- 刷新分布式缓存
结论
Redis是实现Pub/Sub最常用的工具之一。它因扩展性、低延迟和易于集成而广为人知。我们也在内存块级别探讨了Redis的工作原理。
Redis Pub/Sub是一个高效的分发消息的方法,但我们也要知道它在哪些方面做了优化,以及在哪有陷阱。要想彻底了解的话,那就去研究源码吧!一句话,记得只在可信的环境中使用Redis,并要限制客户端的数量,并且小心处理按照表达式的订阅。